Researchers at the Department of Ophthalmology, Icahn School of Medicine at Mount Sinai, New York, has reported an artificial intelligence (AI) tool, as a “large language model” (LLM), or “chatbot” (OpenAI, GPT-4), has outperformed human ophthalmic specialists in diagnostic and treatment accuracy for retina and glaucoma assessments, “substantiating its role as a promising diagnostic adjunct in ophthalmology”. In a cross-sectional study, with responses graded using a Likert scale, “the LLM chatbot demonstrated comparative proficiency, largely matching if not outperforming” retina and glaucoma subspecialists in “addressing ophthalmological questions and patient case management”. The findings “underscore the potential utility of LLMs as valuable diagnostic adjuncts in ophthalmology, particularly in highly specialized and surgical subspecialties of glaucoma and retina”.
The study was aimed to compare the diagnostic accuracy and comprehensiveness of responses from an LLM chatbot with those of fellowship-trained retina and glaucoma specialists on ophthalmological questions and real patient case management. The researchers recruited 15 participants aged 31 to 67 years, including 12 attending physicians and 3 senior trainees, from eye clinics affiliated with the Department of Ophthalmology at Icahn School of Medicine at Mount Sinai, New York. Questions were randomly selected from the American Academy of Ophthalmology’s Commonly Asked Questions and cases (10 of each type) were randomly selected from ophthalmology patients seen at Icahn School of Medicine. The LLM used was GPT-4 (OpenAI). Following the results, focused on retina disease, showed that the mean rank for accuracy was 235.3 for the LLM chatbot, versus 216.1 for the human retina specialists (n = 440; Mann-Whitney U = 15518.0; P = .17). The mean rank for completeness was 258.3 and 208.7, respectively (n = 439; Mann-Whitney U = 13123.5; P = .005). A Dunn test (the appropriate nonparametric pairwise multiple-comparison procedure when a Kruskal–Wallis test is rejected) revealed “a significant difference between all pairwise comparisons, except specialist vs. trainee in rating chatbot completeness. The overall pairwise comparisons showed that both trainees and specialists rated the chatbot’s accuracy and completeness more favourably than those of their specialist counterparts, with specialists noting a significant difference in the chatbot’s accuracy (z = 3.23; P = .007) and completeness (z = 5.86; P < .001)”.
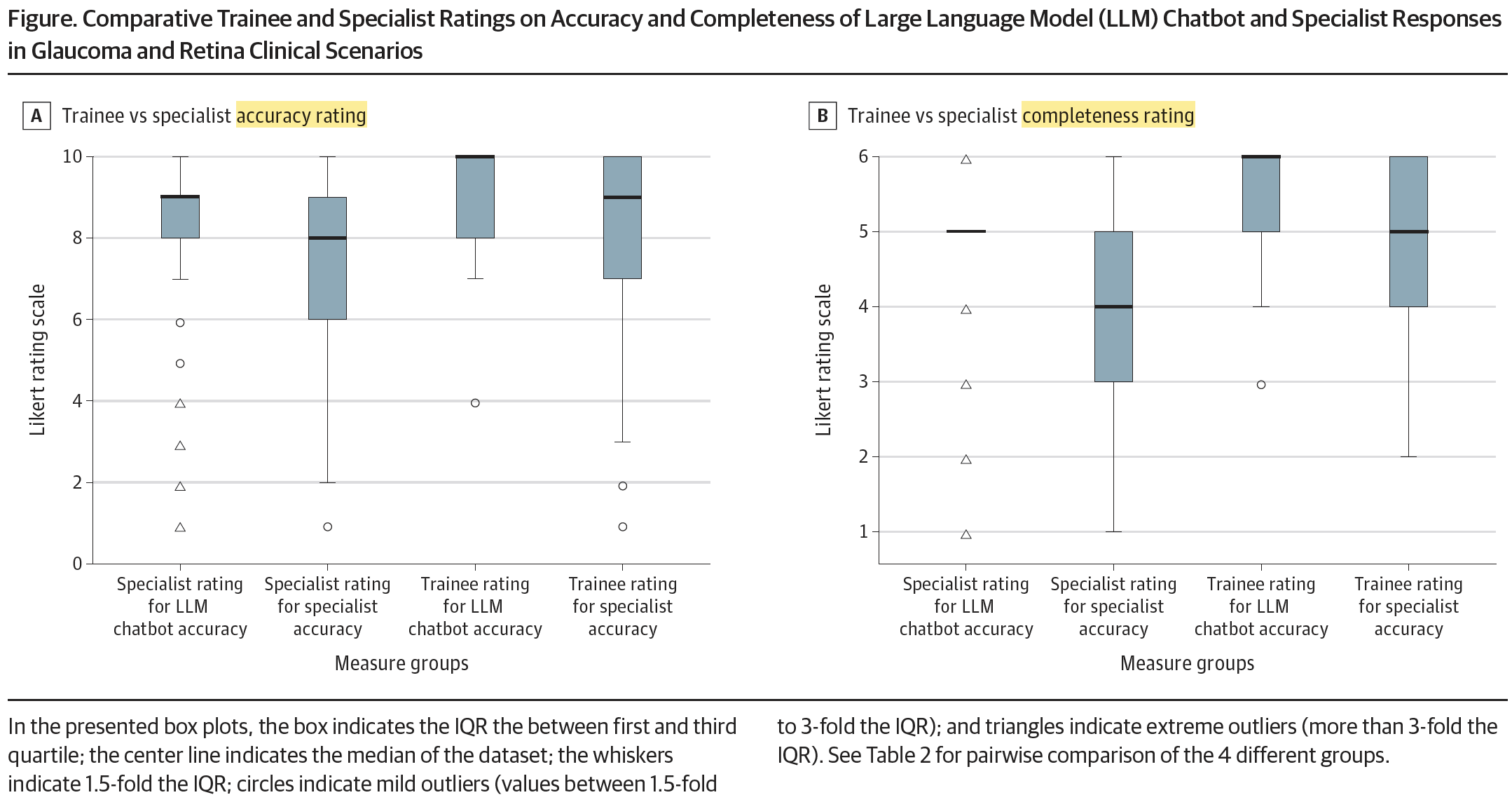
[Open Access: This figure is an open access article distributed under the terms of the CC-BY License. © 2024 Huang AS et al. JAMA Ophthalmology].
According to the researchers, ”the chatbot’s performance relative to retina specialists showed a more balanced outcome, matching them in accuracy but exceeding them in completeness. The LLM chatbot exhibited consistent performance across pair wise comparisons, maintaining its accuracy and comprehensiveness standards for the questions and clinical scenarios. The enhanced performance of the chatbot in our study compared with other evaluations could be attributed to the refined prompting techniques used, specifically instructing the model to respond as a clinician in an ophthalmology note format. These findings support the possibility that artificial intelligence tools could play a pivotal role as both diagnostic and therapeutic adjuncts”.